




合作客戶/
拜耳公司 |
同濟大學 |
聯合大學 |
美國保潔 |
美國強生 |
瑞士羅氏 |






相關新聞Info
大幅提高新藥篩選速度,對包含110億種化合物的虛擬庫進行快速篩選
來源:生物世界 瀏覽 640 次 發布時間:2022-09-16
高通量篩選(HTS)和虛擬配體篩選(VLS)的標準庫歷來被限制在不到1000萬個可用化合物,與潛在的1060個類藥物化合物的巨大化學空間相比,這只是一小部分。標準HTS和VLS的這種局限性減慢了藥物發現的速度。
后來,包含數十億化合物的虛擬庫被開發出來。但隨著虛擬庫的規模增加到數十億,篩選庫中所包含的分子在計算上變得不切實際,而且成本過高。比如,使用1個CPU篩選100億個化合物可能需要3000年以上(以每個化合物10秒的標準速率對接)。
因此,需要更有效的方法來搜索大規模的化合物庫。
2021年12月15日,美國南加州大學、東北大學和北卡羅來納大學教堂山分校的研究團隊合作,在Nature發表了題為:Synthon-based ligand discovery in virtual libraries of over 11 billion compounds的研究論文。
該研究開發了一種從包含110億種化合物的虛擬庫中識別潛在藥物分子的創新方法,并以3個目標蛋白的抑制劑篩選為例,展示了該方法的性能。

用于巨大化學庫的虛擬篩選方法
研究團隊開發了一種被稱為V-SYNTHES的方法(virtual synthon hierarchical enumeration screening,虛擬合成子分級枚舉篩選),大大減少了在這些庫中搜索潛在hits時需要評估的分子數量,使用的計算資源是標準方法的百分之一。
該方法可輕松擴展以適應組合庫的快速增長,并且可能適用于任何對接算法。
V-SYNTHES的工作流程和結果
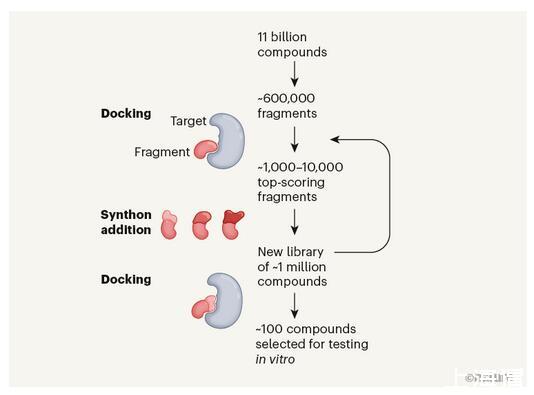
圖1一種處理巨大化學庫的虛擬藥物篩選方法
該方法的流程如下
1.首先建立一個小型的虛擬庫。從110億個分子庫中選擇了大約60萬個片段,這些片段代表整個虛擬庫中存在的所有不同的骨架。稱之為最小列舉庫(minimal enumeration library,MEL)。
2.將MEL庫中的片段與3個目標蛋白對接,計算這些片段與每個蛋白的結合親和力。
3.選擇對接分數最高的1,000-10,000個片段,并向它們添加了合成子(synthons,分子的小片段),創建了一個約有100萬個分子的新庫。
通過重復對接和添加合成子的步驟,篩選幾百萬個化合物來確定hits。隨著每一次迭代,每個化合物的大小都會隨著分子變得更加完整而增加。
4.幾千個排名靠前的VLS化合物經過PAINS、物理化學性質、藥物相似性、新穎性和化學多樣性的后處理過濾,最終選擇有限的化合物集(通常是50-100個)進行合成和實驗測試。
作者發現,在V-SYNTHES預測的與這些受體結合并在低化合物濃度下抑制其活性的前60個化合物中,約有三分之一確實在體外顯示了這種效應。這個"hit獲得率"大約是作者使用的標準方法的兩倍,而V-SYNTHES需要的計算資源比這些方法少100倍。
作者隨后在一種叫做ROCK1的激酶上測試了V-SYNTHES,并報告了28.5%的hit獲得率。在被選中進行合成和體外測試的21個最有希望的化合物中,有6個可以與ROCK1酶結合,并在化合物濃度低于10微摩爾時對其進行抑制。這些化合物可以成為藥物發現計劃中進一步優化的合適線索。
V-SYNTHES的價值和意義
V-SYNTHES代表了藥物發現初始階段的兩種主要方法(基于結構的藥物設計和基于片段的藥物設計)的結合。在基于結構的設計中,分子的結構特征及其與靶點的相互作用被用來指導設計過程。在基于片段的藥物設計中,分子基團被添加到最初因其潛在活性而被確定為有前途的片段中。
這篇論文為從現在可用的大型化合物庫中識別生物活性分子鋪平了道路,使用的計算資源和時間僅為標準虛擬篩選方法的一小部分,而且成功率更高。最重要的是,該方法的計算成本隨著使用的合成子的數量而增加,而不是隨著初始的主要庫的大小而增加。因此,隨著現成的化合物庫及其組合的不斷增加,該方法將繼續具有計算上的可行性。
雖然該方法使用ICM-Pro對接并應用于Enamine REAL Space庫,但基于迭代合成子的篩選算法可以在任何可靠的基于對接的篩選平臺上實現,并在任何可以表示為骨架和合成子組合的超大型庫中使用。在操作過程中可能需要對算法的某些參數進行自定義調整以獲得最佳性能,從而為進一步探索該方法開辟了許多途徑。
V-SYNTHES的擴展性意味著用戶將能夠在特別大的虛擬化合物庫中搜索并找到具有生物活性的分子。該方法不能保證找到最好的hits,但這可能并不重要,因為次優的hits往往為藥物開發過程提供了良好的起點。
不過從長遠來看,虛擬篩選的更大問題是,無論該方法如何快速,其結果都取決于對接步驟的準確性。如同所有的虛擬篩選方法一樣,V-SYNTHES識別良好hits的能力取決于對接分數的準確性,需要有真正可靠的對接分數被開發出來。